Setup your own Raspberry PI 2 Hadoop 2 cluster (Raspberry PI 2 Model B and Hadoop 2.7.2) on Rasbian Linux. For some background and general information around Hadoop please see my previous post:
http://www.widriksson.com/raspberry-pi-hadoop-cluster/
Contents
The Setup
- 3x Raspberry PI 2 Model B
 (4core CPU, 1GB RAM)
(4core CPU, 1GB RAM) - 3x 16gb MicroSDHC cards (Sandisk UHS-I 10x)
- Rasbpian Jessie Lite
(Linux 4.1.17-v7+) - Oracle Java java version 1.8.0_65
- Hadoop 2.7.2 (ARM native compiled from source)

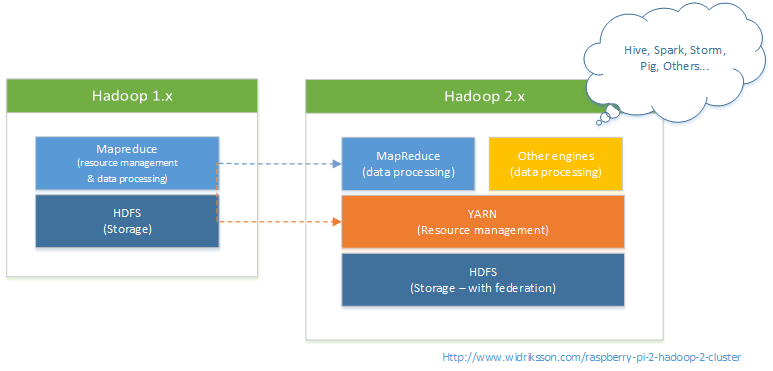
Difference Hadoop 1.x vs. Hadoop 2.x
Some of the more major differences are:
- YARN (Yet Another Resource Negotiator) – Next generation MapReduce (MRv2)
- Separation of processing engine and resource management which was implemented in Hadoop 1.x mapreduce
- In Hadoop 1.x all processing was done through the mapreduce framework. With Hadoop 2.x the use of other data processing frameworks is possible
- TaskTracker slots are replaced with containers which are more generic
- Hadoop 2.x MapReduce programs are backward compatible with Hadoop 1.x MapReduce
- Overall increased scalability and performance
- HDFS Federation – Possible to use multiple namenode servers to manage namespace which allows for horizantal scaling
Depricated properties
See the following urls for properties that are depricated from Hadoop 1.x:
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/DeprecatedProperties.html
Web Interface (default ports)
With Yarn and MapReduce 2 (MR2) http ports for monitoring have changed:
| TCP Port | Application | Configuration property |
|---|---|---|
| 8032 | ResourceManager Client RPC | yarn.resourcemanager.address |
| 8030 | ResourceManager Scheduler RPC | yarn.resourcemanager.scheduler.address |
| 8033 | ResourceManager Admin RPC | yarn.resourcemanager.admin.address |
| 8088 | ResourceManager Web UI and REST APIs | yarn.resourcemanager.webapp.address |
| 8031 | ResourceManager Resource Tracker RPC | yarn.resourcemanager.resource-tracker.address |
| 8040 | NodeManager Localizer RPC | yarn.nodemanager.localizer.address |
| 8042 | NodeManager Web UI and REST APIs | yarn.nodemanager.webapp.address |
| 10020 | Job History RPC | mapreduce.jobhistory.address |
| 19888 | Job History Web UI and REST APIs | mapreduce.jobhistory.webapp.address |
| 13562 | Shuffle HTTP | mapreduce.shuffle.port |
Install Raspbian and prepare environment for Hadoop
Rasbian installation
Download Raspbian Jessie Lite:
https://www.raspberrypi.org/downloads/raspbian/
Write to SD card (use any tool of choice) for windows I use:
https://sourceforge.net/projects/win32diskimager/
Plugin in SD card and fire up your PI.
For inital configuration (raspi-config)
- Expand filesystem
- Under 9 Advanced Options -> A3 Memory Split
Choose 16MB to give as much RAM as possible for Hadoop
If you wish you may also try to overlcock the PI a bit to improve performance. For this tutorial I use default.
Configure network
Login as pi (default password: raspberry)
Edit (as root with sudo -s):
/etc/dhcpcd.conf
At the bottom of the file add:
interface eth0 static ip_address=192.168.0.110/24 # static ip_address=192.168.0.111/24 # static ip_address=192.168.0.112/24 static routers=192.168.0.1
static domain_name_servers=123.123.123.123 123.123.123.123
Change domain name servers to your environment. Note that we are not required to make any changes to /etc/interfaces in Raspbian Jessie.
Update system and install Oracle Java
sudo apt-get update && sudo apt-get install oracle-java7-jdk
Run update-alternatives, ensure jdk-8-oracle-*** is selected:
sudo update-alternatives --config java
Configure Hadoop user
Create a new user for use with Hadoop:
sudo addgroup hadoop sudo adduser --ingroup hadoop hduser sudo adduser hduser sudo
Create SSH paris keys with blank password. This will enable nodes to communicate with each other in the cluster.
su hduser mkdir ~/.ssh ssh-keygen -t rsa -P "" cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
Login as hduser (answer yes when prompted to trust certificate key – otherwise Hadoop will fail to login later)
su hduser ssh localhost exit
Compile Native Hadoop 2.7.2 for Raspberry PI (ARM)
Ensure you have logged out as hduser and logged in as pi user. (for sudo command below to work properly)
Install protobuf 2.5.0
This is required to build Hadoop.
wget https://protobuf.googlecode.com/files/protobuf-2.5.0.tar.gzwget https://github.com/google/protobuf/releases/download/v2.5.0/protobuf-2.5.0.tar.gz tar xzvf protobuf-2.5.0.tar.gz cd protobuf-2.5.0 ./configure --prefix=/usr make make check sudo make install
Install Hadoop 2.7.2
Download and build
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.2/hadoop-2.7.2-src.tar.gz tar xzvf hadoop-2.7.2-src.tar.gz
Java 8 uses a more strict syntax than previous version. We need to be less strict to be able to compile Hadoop 2.7.2. To fix this edit:
hadoop-2.7.2-src/pom.xml
Between <properties></properties> tags insert the following:
<additionalparam>-Xdoclint:none</additionalparam>
For Hadoop 2.7.2 to build properly we also need to apply a patch.
cd hadoop-2.7.2-src/hadoop-common-project/hadoop-common/src wget https://issues.apache.org/jira/secure/attachment/12570212/HADOOP-9320.patch patch < HADOOP-9320.patch
cd ~/hadoop-2.7.2-src/
To start build Hadoop run the following: (Note this may take ~1,5 hours)
sudo mvn package -Pdist,native -DskipTests -Dtar
Install
Copy compiled binaries to /opt
cd hadoop-dist/target/ sudo cp -R hadoop-2.7.2 /opt/hadoop
Give access to hduser
sudo chown -R hduser.hadoop /opt/hadoop/
Verify installation and native libraries
su hduser cd /opt/hadoop/bin hadoop checknative -a
16/03/24 20:20:03 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
16/03/24 20:20:03 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
Native library checking:
hadoop: true /opt/hadoop/lib/native/libhadoop.so.1.0.0
zlib: true /lib/arm-linux-gnueabihf/libz.so.1
snappy: true /usr/lib/libsnappy.so.1
lz4: true revision:99
bzip2: true /lib/arm-linux-gnueabihf/libbz2.so.1
openssl: true /usr/lib/arm-linux-gnueabihf/libcrypto.so
Check version
hadoop version
Hadoop 2.7.2
Subversion Unknown -r Unknown
Compiled by root on 2016-02-21T19:05Z
Compiled with protoc 2.5.0
From source with checksum d0fda26633fa762bff87ec759ebe689c
This command was run using /opt/hadoop/share/hadoop/common/hadoop-common-2.7.2.jar
Configure environment variables
In /etc/bash.bashrc, add to bottom of file:
export JAVA_HOME=$(readlink -f /usr/bin/java | sed “s:jre/bin/java::”)
export HADOOP_INSTALL=/opt/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_HOME=$HADOOP_INSTALL
Edit and change varibales in Hadoop environment.sh (/opt/hadoop/etc/hadoop/)
Find out your java home (readlink -f /usr/bin/java | sed “s:jre/bin/java::).
export JAVA_HOME=/usr/lib/jvm/jdk-8-oracle-arm32-vfp-hflt
Enable the use of native hadoop library and IPv4 stack:
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_INSTALL/lib/native -Djava.net.preferIPv4Stack=true"
Hadoop 2.7.x YARN and MapReduce memory and resources configuration
Some of the challanges of running Hadoop on the Raspberry is the limited resources. In order for it to run properly we will need to adjust memory configuration of YARN and Mapreduce framework.
Slots in Hadoop 1.x vs. containers in Hadoop 2.x
In Hadoop 1.x each map or reduce task occupied a slot regardless of how much memory or cpu it used. In Hadoop 2.x YARN is coordinating resources (such as RAM, CPU and disk) among different applications that is running on the cluster. This allows for more dynamic and efficient use of resources. YARN will allocate resources to applications (MapReduce, Spark, Impala etc..) by using containers. A container is a unit of processing capacity in YARN. Each application in the cluster will request processing capacity from YARN which then in turn is provided by a processing container. When the applicaiton reuqest the container the request also contains information about how much resources it would like to use. YARN is then balancing and negoitating the resource requests on the cluster. For the purpose of this tutorial we will look into the memory configuration.
YARN Configuration (yarn-site.xml)
For more details see: https://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
| Property | Default | Our | Desription |
|---|---|---|---|
| yarn.nodemanager.resource.memory-mb | 8192 | 768 | Amount of physical memory, in MB, that can be allocated for containers |
| yarn.scheduler.minimum-allocation-mb | 1024 | 64 | Minimum amount of memory YARN will allocate for a container. An application should ask for at least this amount of memory or more. If it ask for more YARN will round it up to the closest unit of yarn.scheduler.minimum-allocation-mb. For example if we have a minimum allocation of 2048mb and an application asks for 3072mb it will receieve a container of 4096mb |
| yarn.scheduler.maximum-allocation-mb | 8192 | 256 | Maximum amount of memory YARN will allocate for a container |
| yarn.nodemanager.vmem-check-enabled | true | true | true/false, weather enforced virtual memory limit will be enabled |
| yarn.nodemanager.vmem-pmem-ratio | 2.1 | 2.1 | Ratio of virtual to physical memory when applying memory limit for containers |
| yarn.nodemanager.pmem-check-enabled | true | true | true/false, weather enforced physical memory limit will be enabled |
In case memory would exceed physical/virtual memory limits you will receieve errors similar to below when running mapreduce jobs:
16/05/12 10:07:02 INFO mapreduce.Job: Task Id : attempt_1463046730550_0002_m_000006_0, Status : FAILED Container [pid=20945,containerID=container_1463046730550_0002_01_000047] is running beyond virtual memory limits. Current usage: 38.2 MB of 128 MB physical memory used; 484.2 MB of 268.8 MB virtual memory used. Killing container. Dump of the process-tree for container_1463046730550_0002_01_000047 : |- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE |- 20945 20941 20945 20945 (bash) 1 2 3121152 493 /bin/bash -c /usr/lib/jvm/jdk-8-oracle-arm32-vfp-hflt/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx404m -Djava.io.tmpdir=/hdfs/tmp/nm-local-dir/usercache/hduser/appcache/application_1463046730550_0002/container_1463046730550_0002_01_000047/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/hadoop/logs/userlogs/application_1463046730550_0002/container_1463046730550_0002_01_000047 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.0.110 48748 attempt_1463046730550_0002_m_000006_0 47 1>/opt/hadoop/logs/userlogs/application_1463046730550_0002/container_1463046730550_0002_01_000047/stdout 2>/opt/hadoop/logs/userlogs/application_1463046730550_0002/container_1463046730550_0002_01_000047/stderr |- 20952 20945 20945 20945 (java) 668 36 504578048 9288 /usr/lib/jvm/jdk-8-oracle-arm32-vfp-hflt/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx404m -Djava.io.tmpdir=/hdfs/tmp/nm-local-dir/usercache/hduser/appcache/application_1463046730550_0002/container_1463046730550_0002_01_000047/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/hadoop/logs/userlogs/application_1463046730550_0002/container_1463046730550_0002_01_000047 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.0.110 48748 attempt_1463046730550_0002_m_000006_0 47 Container killed on request. Exit code is 143 Container exited with a non-zero exit code 143
MapReduce 2 configuration properties (mapred-site.xml)
For more details see:
https://hadoop.apache.org/docs/r2.7.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
| Property | Default | Our | Desription |
|---|---|---|---|
| mapreduce.framework.name | local | yarn | The runtime framework for executing MapReduce jobs. Can be one of local, classic or yarn |
| mapreduce.map.memory.mb | 1024 | 256 | The amount of memory to request from the scheduler for each map task |
| mapreduce.map.java.opts | -Xmx1024M | -Xmx204M | Java opts (Max JVM heap size for map task. (Should be less than mapreduce.map.memory.mb, common recommendation 0.8 * mapreduce.map.memory.mb)) |
| mapreduce.map.cpu.vcores | 1 | 2 | Number of CPU’s availible for map tasks |
| mapreduce.reduce.memory.mb | 1024 | 102 | Max amount of memory for reduce task |
| mapreduce.reduce.java.opts | -Xmx2560M | -Xmx102M | Java opts (Max JVM heap size for reduce task. (Should be less than mapreduce.reduce.memory.mb, common recommendation 0.8 * mapreduce.reduce.memory.mb)) |
| mapreduce.reduce.cpu.vcores | 1 | 2 | Number of CPU’s availible for reduce tasks |
| yarn.app.mapreduce.am.resource.mb | 1536 | 128 | Max amount of memory for App Master |
| yarn.app.mapreduce.am.command-opts | -Xmx1024m | -Xmx102M | Java opts (Max JVM heap size for App Master) |
| yarn.app.mapreduce.am.resource.cpu-vcores | 1 | 1 | Max amount of CPU’s for App Master |
| mapreduce.job.maps | 2 | 2 | The default number of map tasks per job. Ignored when mapreduce.jobtracker.address is “local” |
| mapreduce.job.reduces | 1 | 2 | The default number of reduce tasks per job. Ignored when mapreduce.jobtracker.address is “local” |
YARN and MapReduce memory configuration overview
With our setup using the values above the YARN resource manager could potentially give use the following scenarios below when running MapReduce jobs:


The idea is that we try to utilize as much RAM and CPU power out of our PI as possible.
Configure Single Node
Edit configuration files in /opt/hadoop/etc/hadoop
core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/hdfs/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:54310</value> </property> </configuration>
hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.blocksize</name> <value>5242880</value> </property> </configuration>
| Property | Default | Our | Description |
|---|---|---|---|
| dfs.replication | 3 | 1 | By default hadoop replicates data on 3 nodes. Since we only have one node we set it to 1 and later switch it to 3. |
| dfs.blocksize | 134217728 | 5242880 | Default blocksize for new files in bytes. Default value is 128mb. In this tutorial we will use files less than this size and in order for them to scale on Raspberry PI we set this property to 5mb instead. This means that files will be split in chunks of 5mb in our cluster when distributed among nodes and also each of our mapreduce tasks will work with 5mb at a time. |
For a complete list of properties for hdfs-default.xml: https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
slaves
Currently we only have one node. Keep default value of localhost. We will later add all our nodes here for a multi-node setup.
localhost
yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>node1:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>node1:8035</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>node1:8050</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>768</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>64</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>256</value> </property> <property> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>1</value> </property> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>4</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> </configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx204m</value>
</property>
<property>
<name>mapreduce.map.cpu.vcores</name>
<value>2</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>128</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx102m</value>
</property>
<property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>128</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx102m</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>mapreduce.job.maps</name>
<value>4</value>
</property>
<property>
<name>mapreduce.job.reduces</name>
<value>4</value>
</property>
</configuration>
Format HDFS filesystem
sudo mkdir -p /hdfs/tmp sudo chown hduser:hadoop /hdfs/tmp sudo chmod 750 /hdfs/tmp hadoop namenode -format
Start Hadoop
Run the following commands as hduser:
start-dfs-sh start-yarn.sh
Verify that all services started correctly:
jps
Result should show the following active processes:
1413 NodeManager
838 NameNode
1451 Jps
1085 SecondaryNameNode
942 DataNode
1311 ResourceManager
If all processes not are visible review log files in /opt/hadoop/logs
Run hadoop hello world – wordcount
Download sample files (From my preivous blog post)
Run all commands as hduser. Extract the files to home directory of hduser.
tar -xvzf hadoop_sample_txtfiles.tar.gz ~/
Upload files to HDFS:
hadoop fs -put smallfile.txt /smallfile.txt hadoop fs -put mediumfile.txt /mediumfile.txt
Execute wordcount example from source code folder (~/hadoop-2.7.2-src/hadoop-mapreduce-project/hadoop-mapreduce-examples/target/):
time hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /smallfile.txt /smallfile-out time hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /mediumfile.txt /mediumfile-out
Result:
| File | Size | Using Raspberry PI 1 | Raspberry PI 2 (this setup) |
|---|---|---|---|
| smallfile.txt | 2MB | 2:17 | 1:47 |
| mediumfile.txt | 35MB | 9:19 | 5:50 |
When you execute the job you will also see that there is an http url to track progress:
lynx http://node1:8088/proxy/application_1463048023890_0002 (Url will be unique to your execution, see url when you start the job – you may use any browser in this case I used Lynx)
![]()
When this snapshot was taken we can see that we have one runing map task and 2 running reduce tasks which looks good concerning our anticipated memory allocation outcome here.
Configure Multiple Nodes
Clear HDFS filesystem
rm -rf /hdfs/tmp/* hdfs namenode -format
Edit configuration files
/etc/hostname
node1/node2/node3
/etc/hosts
192.168.0.110 node1 192.168.0.111 node2 192.168.0.112 node3
/etc/dhcpcd.conf
interface eth0
static ip_address=192.168.0.110/24
# static ip_address=192.168.0.111/24
# static ip_address=192.168.0.112/24
static routers=192.168.0.1
static domain_name_servers=123.123.123.123 123.123.123.123
/opt/hadoop/slaves
node1
node2
node3
/opt/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hdfs/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:54310</value>
</property>
</configuration>
/opt/hadoop/hdfs-site.xml
By changing this to 3 we will ensure that we have data locally on each node when we add new files (assuming we have 3 nodes in our cluster)
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
/opt/hadoop/yarn-site.xml
<property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>node1:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>node1:8035</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>node1:8050</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
Clone SD-Card
Use Win32 imager or any other software of your choice to clone the sd-card. After clone ensure to configure each node with new hostname and ip-address.
Also ensure to configure /etc/hostname and /etc/dhcpcd.conf on each node correctly with IP/hostname.
Login with ssh to all nodes to fix host key verification
Logon with ssh to all nodes from namenode (node1). Enter Yes when you get the “Host key verification failed message”. This is important in order for namenode to be able to communicate with the other nodes without entering a password.
Start services
Run the following commands as hduser:
start-dfs-sh start-yarn.sh
Run jps command on all nodes to ensure all services started fine. On the data/processing nodes you should have the following services:
hduser@node2:~ $ jps 1349 DataNode 1465 NodeManager 1582 Jps
And on the namenode (node1) you should have the following:
hduser@node1:/home/pi $ jps 3329 ResourceManager 2851 NameNode 3435 NodeManager 3115 SecondaryNameNode 3742 Jps 2959 DataNode
Performance comparison to Raspberry PI 1 Model B (512mb)
Run wordcount as done in previous step. As we can see there is a significant difference using the newer Raspberry PI 2:
| File | Size | Using Raspberry PI 1 | Raspberry PI 2 (this setup – 3 nodes) |
|---|---|---|---|
| smallfile.txt | 2MB | 2:17 | 1:41 |
| mediumfile.txt | 35MB | 9:19 | 2:22 |
| (larger file) | 431MB | N/A | 17:10 |
For fun I also tried to include a larger file to see if the PI’s could put up with it. They did fine but I got some containers killed due to memory issues but that could probably be tweaked further.
Happy data crunching! 🙂
References
http://www.instructables.com/id/Native-Hadoop-260-Build-on-Pi/
http://stackoverflow.com/questions/32823375/compiling-hadoop-2-7-1-on-arm-raspbian
http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-1/
https://www.mapr.com/blog/managing-monitoring-and-testing-mapreduce-jobs-managing-jobs-and-tasks
http://arturmkrtchyan.com/how-to-setup-multi-node-hadoop-2-yarn-cluster
Hi,
Thanks for your tutorial. I would like create a Pi zero cluster (only learning purpose). Do you if the process is the same ? suppose i’m connected by wifi
Thanks,
BJ
Hi Jones!
I have not tried the Zero but should be the same process. You might need to tweak the memory configuration in Hadoop to make it run properly on 512mb though.
//Jonas
I have 3 new RPi3, which I was trying to setup with Hadoop 2.7.2 using your old V1 install blog, and working out what to do at each step of the way for differences of V2.7.2. I was glad to see that you posted this recently, saved me some work once I saw it, thanks.
My 3 RPi3 run the mediumfile.txt processing in around 1m30sec.
I didn’t install the different Java, just used the one that was pre-installed in the Raspbian Jessie distribution.
I also did not compile Hadoop myself, I just got the package from http://apache.mirrors.spacedump.net/hadoop/core/stable/hadoop-2.7.2.tar.gz
Is there a special reason that you got the Oracle Java, and compiled Hadoop locally?
I put instructions of how I set mine up (much of your steps here with whatever I did a bit different) and copies of various config files and short-cut scripts into a GitHub repo at https://github.com/phil-davis/HadoopRPi3
Anyone feel free to make use of any of that how you wish.
Thanks for the guide! I just got hadoop running on a 4 node odroid cluster with some help from your tutorial and a few other sources. I used the jar version of hadoop instead of compiling it from source myself, but I might change that in the future. My current benchmark seems to be ~11.5 minutes to perform wordcount on a 431 MB file (which I created by cat-ing mediumfile.txt onto itself over and over again).
I ran into some problems with home network configurations. I have a home router, a second router I use as a switch, and the switch I used for the hadoop cluster. The hadoop cluster’s switch likes registering itself as 192.168.0.1, which conflicted with the main router I connect directly to my modem, and when I set my nodes to use static IPs, they tried to use the main router as a gateway and got the switch instead.
I spent a fair deal of time struggling with how I set up static IPs for my cluster. I think at some point I added my hostname as an entry in /etc/hosts assigned to 127.0.0.1, and then added it again when I moved from single node to cluster operation, so a lot of my services weren’t actually listening to network traffic.
I ran into fairly extensive problems with memory management. Since the Odroid has 2 GB of memory instead of 1 GB on the Pi, I tried doubling most of the maximum and overall memory allocations, but there was a relationship between vmem-pmem ratio and overall pmem that I missed somehow, and I had a bunch of problems with overallocating virtual memory.
I still seem to be having at least intermittent problems, but I’m having more trouble reproducing my problems now. When I have those problems, they’re usually still related to overallocated virtual memory.
Thanks for the tutorial.
However, I am getting stuck on the step:
sudo mvn package -Pdist,native -DskipTests -Dtar
I am using a Pi 3, connected through WiFi, and when I type this command into terminal, I get the error:
sudo: mvn: Command not found
So, after some research, I was able to get it to work using
sudo env “PATH=$PATH” mvn package -Pdist,native -DskipTests -Dtar
Then maven starts to do its magic, but when Hadoop is being built, the entire process terminates, because Hadoop HTTPFS received an error.
I can send you an eMail with the Screenshots from Terminal, if you would be willing to help me. It would be a great gesture, and I will be sure to pay it forward as well
I followed the guide and it does not work for me. I successfully compiled, deployed the package, all ssh connectivity are tested for 2 RPi, hosts and hostname also validated, however when I run “hadoop fs -ls /”, I encountered failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused.
Anyone can help out please?
If you run the jps command can you verif that all services have started? //Jonas
Same problem here. jps confirms that all services are running.
I’m experiencing the same problem as AC. jps shows all services are running.
What strikes me as strange that nestat -a does not show any hadoop service listening
Thanks for the comments. I saw that I accidently kept node1 as hostname in core-site.xml and yarn-site.xml for the single node setup. In the single node setup use localhost for hostname references in core-site-xml and yarn-site.xml. I have updated the tutorial.
//Jonas
Hmm, I had already corrected that, but still got the authorization problem. B.t.w. the formatting of the 2 xml-files you mention is now off, they are almost unreadable now. You may want to correct that. Any other ideas where the authorization problem stems from?
Thanks for this great guide. I’m learning a ton. I’m running on a B+ model jesse 8.0 lite.
On the ./hadoop checknative -a I’m getting a false on snappy and bzip2.
bzip2 is installed (version 1.0.6)
Does it matter? Can it be fixed?
Thanks again!
Check that – I successfully compiled on a 2B with 1 GB.
Now I’m trying to compile on a B+ with 512MB.
I’m getting a: Java.lang.OutOfMemoryError: Java heap space
[INFO] Compiling 852 source files to /home/pi/hadoop-2.7.2-src/hadoop-common-project/hadoop-common/target/classes
[INFO] Apache Hadoop Main …………………………… SUCCESS [ 19.520 s]
[INFO] Apache Hadoop Project POM …………………….. SUCCESS [ 17.692 s]
[INFO] Apache Hadoop Annotations …………………….. SUCCESS [ 43.565 s]
[INFO] Apache Hadoop Assemblies ……………………… SUCCESS [ 3.967 s]
[INFO] Apache Hadoop Project Dist POM ………………… SUCCESS [ 18.825 s]
[INFO] Apache Hadoop Maven Plugins …………………… SUCCESS [ 46.943 s]
[INFO] Apache Hadoop MiniKDC ………………………… SUCCESS [ 39.553 s]
[INFO] Apache Hadoop Auth …………………………… SUCCESS [ 51.357 s]
[INFO] Apache Hadoop Auth Examples …………………… SUCCESS [ 54.245 s]
[INFO] Apache Hadoop Common …………………………. SKIPPED
[INFO] Final Memory: 55M/106M
I set export MAVEN_OPTS=”-Xms512m -Xmx1024m”, but it didn’t seem to make a difference. Not sure what the values should be anyway.
Thanks,
Not sure what I did wrong here…
pi@controller:~ $ su hduser
Password:
hduser@controller:/home/pi $ mkdir ~/.ssh
hduser@controller:/home/pi $ ssh-keygen -t rsa -P “”
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hduser/.ssh/id_rsa):
key_save_private: No such file or directory
Saving the key failed: cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys.
hduser@controller:/home/pi $ ssh-keygen -t rsa -P “”
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hduser/.ssh/id_rsa): SSH_Key
key_save_private: Permission denied
Saving the key failed: SSH_Key.
I think you created the .ssh in the /home/pi dir instead of the /home/hduser.
WHen you do the su command put a – between su and hduser, like this su – hduser. using the hyphen changes your dir to the home dir of the user and sets that users env variables.
Hope this helps!
Stan
Great write-up! I really appreciate the details.
However when I run the “sudo update-alternatives –config java”, it shows that nothing is configured as shown below. I’d appreciate any help so that I will have the jdk-8 as you suggested.
Thanks,
Vince
============================================
pi@RPI3-node1:~ $ sudo update-alternatives –config java
There is only one alternative in link group java (providing /usr/bin/java): /usr/lib/jvm/jdk-7-oracle-arm-vfp-hflt/jre/bin/java
Nothing to configure.
having problems when it comes to httpFS they pom.xml dont exist. has anyone come across this yet?
Downloading: https://repository.apache.org/content/repositories/snapshots/com/googlecode/json-simple/json-simple/1.1/json-simple-1.1.pom
Downloading: http://repository.jboss.org/nexus/content/groups/public/com/googlecode/json-simple/json-simple/1.1/json-simple-1.1.pom
Downloading: https://repo.maven.apache.org/maven2/com/googlecode/json-simple/json-simple/1.1/json-simple-1.1.pom
Want to notice that your protobuf src(https://protobuf.googlecode.com/files/protobuf-2.5.0.tar.gz) doesn’t work anymore now. The following is the currently available link for protobuf 2.5.0 release, check i t out.
https://github.com/google/protobuf/releases/download/v2.5.0/protobuf-2.5.0.tar.gz
Love you work.
Hi
I recently ( 5-Dec=-2016) started building using this pretty good blog. I soon found the links problem as mentioned by Hukly, no problem, the github linked worked great.
But … during the “Install protobuf 2.5.0” phase,
wget https://github.com/google/protobuf/releases/download/v2.5.0/protobuf-2.5.0.tar.gz
tar xzvf protobuf-2.5.0.tar.gz
cd protobuf-2.5.0
./configure –prefix=/usr
make
make check …….
the make check produced the following error messages .. I’ve edited the output to just show the
problems area
does anyone know why we’re getting these errors ?
Tony
[———-] 14 tests from DatabaseSource/AllowUnknownDependenciesTest
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.PlaceholderFile/0
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.PlaceholderFile/0 (1 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.PlaceholderFile/1
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.PlaceholderFile/1 (1 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.PlaceholderTypes/0
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.PlaceholderTypes/0 (1 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.PlaceholderTypes/1
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.PlaceholderTypes/1 (1 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.CopyTo/0
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.CopyTo/0 (1 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.CopyTo/1
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.CopyTo/1 (1 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.CustomOptions/0
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.CustomOptions/0 (2 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.CustomOptions/1
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.CustomOptions/1 (1 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.UnknownExtendee/0
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.UnknownExtendee/0 (1 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.UnknownExtendee/1
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.UnknownExtendee/1 (2 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.CustomOption/0
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.CustomOption/0 (2 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.CustomOption/1
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.CustomOption/1 (2 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.UndeclaredDependencyTriggersBuildOfDependency/0
[libprotobuf ERROR google/protobuf/descriptor.cc:2547] Invalid proto descriptor for file “invalid_file_as_undeclared_dep.proto”:
[libprotobuf ERROR google/protobuf/descriptor.cc:2550] undeclared.Quux.quux: Field number 1 has already been used in “undeclared.Quux” by field “qux”.
[libprotobuf INFO google/protobuf/descriptor_unittest.cc:2107] syntax = “proto2”;
message Corge {
optional .undeclared.Quux quux = 1;
}
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.UndeclaredDependencyTriggersBuildOfDependency/0 (2 ms)
[ RUN ] DatabaseSource/AllowUnknownDependenciesTest.UndeclaredDependencyTriggersBuildOfDependency/1
[libprotobuf ERROR google/protobuf/descriptor.cc:2547] Invalid proto descriptor for file “invalid_file_as_undeclared_dep.proto”:
[libprotobuf ERROR google/protobuf/descriptor.cc:2550] undeclared.Quux.quux: Field number 1 has already been used in “undeclared.Quux” by field “qux”.
[libprotobuf INFO google/protobuf/descriptor_unittest.cc:2107] syntax = “proto2”;
message Corge {
optional .undeclared.Quux quux = 1;
}
[libprotobuf ERROR google/protobuf/descriptor.cc:2547] Invalid proto descriptor for file “invalid_file_as_undeclared_dep.proto”:
[libprotobuf ERROR google/protobuf/descriptor.cc:2550] undeclared.Quux.quux: Field number 1 has already been used in “undeclared.Quux” by field “qux”.
[ OK ] DatabaseSource/AllowUnknownDependenciesTest.UndeclaredDependencyTriggersBuildOfDependency/1 (3 ms)
[———-] 14 tests from DatabaseSource/AllowUnknownDependenciesTest (23 ms total)
[———-] Global test environment tear-down
[==========] 875 tests from 113 test cases ran. (11312 ms total)
[ PASSED ] 875 tests.
PASS: protobuf-test
==================
All 5 tests passed
==================
make[3]: Leaving directory ‘/home/pi/protobuf-2.5.0/src’
make[2]: Leaving directory ‘/home/pi/protobuf-2.5.0/src’
make[1]: Leaving directory ‘/home/pi/protobuf-2.5.0/src’
pi@pi01:~/protobuf-2.5.0 $
Jonas, just wanted to give a massive thanks for publishing this article, I’ve used it a the basis of building a 5 node hadoop cluster running a range of hadoop components with a hue front end.
hadoop 2.6.4
hue 3.11.0
hbase 1.2.4
pig 0.12.1
hive 1.2.1
spark 1.6.2
livy 0.2.0
oozie 4.3.0
sqoop 1.99.4
solr 4.10.4
impala – not supported
Under laboratory conditions it runs everything I’ve tried (although there are some oozie workflows I don’t have dependencies to try out). I’ve done it as a learning exercise but thought you’d want to know about one of the “spin off” projects your work has inspires/contributed to. Here’s the links:
Chef code and config – https://github.com/andyburgin/hadoopi
Tutorial video with step-by-step instructions – https://www.youtube.com/watch?v=YtI9LkIJ7Hc
Blog post – http://data.andyburgin.co.uk/post/157450047463/running-hue-on-a-raspberry-pi-hadoop-cluster
Need to update line:
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.2/hadoop-2.7.2-src.tar.gz
to:
wget http://apache.claz.org/hadoop/common/hadoop-2.7.2/hadoop-2.7.2-src.tar.gz
as the original throws errors:
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Exiting with failure status due to previous errors
running “file” on hadoop-2.7.2-src.tar.gz shows:
hadoop-2.7.2-src.tar.gz: HTML document, ASCII text, with very long lines